Sometimes at work, I’ll need to work in a rather large monorepo. I don’t work in it frequently, which means when I do, the git pull can take hours to complete. I’m not a huge fan of hurrying up and waiting, so I wanted to see if I could do something about this. I spent a few hours today playing around with git and trying to minimize my time spent pulling new updates.
The solution I came up with uses several git features to significantly speed up my times. It uses:
- Partial Clones
- Sparse Checkouts
- Customizing the remote fetch refspec
I’ll cover what each of these does and how it improves my performance. This post isn’t going to be a deep dive into any of these concepts, so if you want more detail on how they work I suggest checking out the git docs. I’ve linked to the resources I used below.
Partial Clones
The first thing I wanted to do was to make sure I only downloaded the minimum number of items required to get the repository in working order. To do this, I leveraged the partial clone feature of git to skip downloading blobs (the contents of files) until they’re needed.
Here’s the command:
| |
To break this down:
--filter=blob:none tells git not to download any file contents until they are needed.--no-checkout ensures that git won’t checkout any branches until I tell it to. This is important for the Sparse Checkout feature I’m using.
Downsides to Partial Clones
Because we’re deferring downloading blobs until we need them, a git checkout may require an active connection to the remote to fetch any missing blobs. It can also increase time spent checking out as git downloads the files you need.
Sparse Checkout
Once I set up my partial clone, I then had to tell git what directories I need. I don’t want to load the entire repo as there are thousands of directories I’ll never touch. To do that, I used a sparse checkout.
I cd into my repo and then used the following command to tell git to use a sparse checkout:
| |
--cone tells git to use “Cone” mode, which is the more performant option in my case. Now I need to add some directories to checkout:
| |
Once this runs, git will only populate files in the root of the repo, and and files/folders located in any of the paths I added. Now git will only download the blobs for files I expect to use.
Customizing the remote fetch refspec
By default git will fetch every branch from the remote. This repo has a lot of engineers working in it, which means there’s a lot of branches. Fetching all of these doesn’t any sense, so we’re going to update our git config to fetch a subset of commits.
All of the branches that my team creates follow this naming convention: myteam/username/feature-name, so I can limit my fetches to just branches starting with myteam/.
| |
The first command removes the default refspec (+refs/heads/*:/refs/remotes/origin/*), then we add two new ones. The main branch and all of the branches with a name starting with myteam/.
Putting it all together
Once all the configs have been set, I was able to checkout the main branch and start working:
| |
Subsequent git pull executions ran significantly faster. Here’s an example execution:
| |
After running the commands, I can see only the folders I care about are in my working tree:
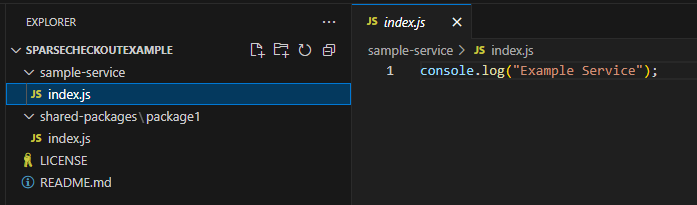
Meanwhile in the repository on GitHub: